Really interesting paper, and article summarising it
tldr; LLMs are still just pattern matching, not thinking.
Really interesting paper, and article summarising it
tldr; LLMs are still just pattern matching, not thinking.
I’ve found it can be quite useful to get a LLM to prepare a summary fact which you tell it to not show to the front end user, but to validate this summary table of calculations and then use this summary to prepare the response. Ie separating like this seems to increase it having an accurate calculation math wise.
Might work the same with reasoning by getting it to formulate a number of items as an intermediary step and then use this to provide “reasoning”?
Similar to how we have different concepts in our head from our experience which we use to formulate a response
It’s a bit of a challenge because the “conversational” part is so closely entwined with the “pattern matching” portion allowing it to exhibit its apparent intelligence.
For example, a lot of applications rely upon probabilistic pattern matching as best human performance – look at something like:
In this article, you have specialist genetic cardiologists being compared with LLM output – and the same patterns cardiologists have been trained upon themselves are those features that bubble up to the top in an LLM. The diagnostic aspect of medicine is, effectively, ranking levels of certainty about various patterns against each other to inform decision-making – so, perfect.
As the substack article shows, however, the “conversational” aspects can lead the LLM astray – partly “poisoning” the features with prefixes and other nearby words can have profound effects on downstream output. It may be the case the cure for “hallucinations” – at least in the short- to medium-term – is not so much within the models themselves, but the responsibility of appropriately constructing prompts to obtain high-quality output.
Good article—and the overview by Gary Marcus. He consistently critiques AI hype well, in my opinion.*
The more I think about LLMs, the more I’m drawn to the conclusion that they are not a replacement for expert thinking, which we need to do properly ourselves—first! Where they can help is then to critique our thoughts and suggest things we might have overlooked.
Dr Jo.
*As a minor aside, a few days ago I wrote a mildly humorous take on the Apple paper here:
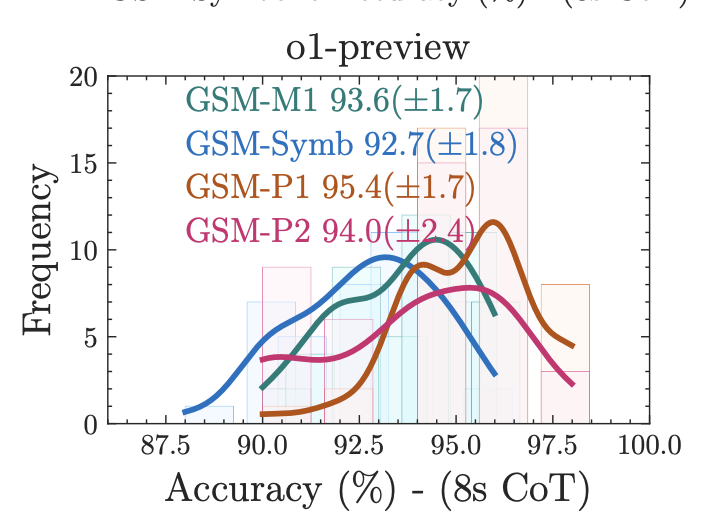
Doesn’t seem to hold up very well with o1-preview which does maybe indicate that reasoning might still be an emergent property of more advanced models. Yes, smaller and less well architected models can’t reason but “However, o1-preview shows very strong results on all levels of difficulty as all distributions are close to each other.” which seems to go against their hypothesis that there is something about the current approaches that means reasoning is not possible. I suspect smaller networks just don’t have the room to contain the kind of architecture needed to do mathematical reasoning. Might also be not enough training data on complex reasoning tasks which seems understandable given the lack of this kind of data on the web compared to other types of text (wikipedia articles, discussion threads, social media, etc.). Perhaps they need a very large dataset of reasoning examples gnenerated automatically.
It wouldn’t necessarily be surprising to find some emergent “reasoning” at some point – after all, human neuronal connections aren’t designed to “do math”, yet the underlying patterns and concepts can be engrained within our neuronal pathways to enable generalisation of methods to do so. What looks like “intelligence” (see: mathematical proofs) – well, it is “intelligence”, in the sense that predicting the next token is akin to using the neuronal-mimicry to find the next step in application of a generalised concept. I do agree LLMs are moving rapidly from “predictive text” to something where the predicted token is internally imbued with meaning from its context and associated vector weightings.
There will definitely be a lot of interesting experiments coming over the next decade – if we can find enough electricity to supply them!
Agreed Re: preview-o1. It is a preview so yet ready for the real world.
Claude 3.5 sonnet (new) appears to be matching Chat GPT pretty well. Personally, I have more faith in the governance of Anthropic of Open AI.
Leaderboard (Simple Bench)
| Rank | Model | Score (AVG@5) | Organization |
|---|---|---|---|
| - | Human Baseline* | 83.7% | |
| 1st | o1-preview | 41.7% | OpenAI |
| 2nd | Claude 3.5 Sonnet 10-22 | 41.4% | Anthropic |